

2025 年如何爬取 Pinterest 数据
在本文中,我将向你介绍两种提取 Pinterest 数据的简单方法。第一种方法使用 Playwright,这是一种无头浏览器,可以让你像真正的用户一样与网页互动。第二种方法依赖于 Scraper API,它能为你处理一切事务,包括 验证码 和动态加载。无论您是想要完全控制,还是想要快速、自动化的解决方案,您都能找到适合自己的方法。让我们开始吧
您能从 Pinterest 提取哪些数据?
在搜索 Pinterest 时,您可以收集:
- 图钉标题 - 描述每个徽章的文字。
- 图钉 URL - 单个引脚的链接。
- 图钉图片 - 与每个图钉相关的图像。
- 用户信息 - 徽章创建者的详细资料。
- 职位聘用 - 赞、评论和分享。
与Playwright一起搜索 Pinterest
Playwright 是一款功能强大的动态网站搜索工具。它能让你与 Pinterest 等 JavaScript 繁重的页面进行交互。
步骤 1:安装 Playwright
首先,安装 Playwright 及其浏览器:
pip install playwright
安装
步骤 2:编写爬虫
下面的 Python 脚本会搜索 Pinterest 上的pins并提取其详细信息:
import asyncio
from playwright.async_api import async_playwright
import json
async def scrape_pinterest(query):
url = f "https://www.pinterest.com/search/pins/?q={query}&rs=typed"
结果 = []
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
页 = await browser.new_page()
await page.goto(url)
await asyncio.sleep(2)
引脚 = await page.query_selector_all("div[data-test-id='pinWrapper']")
for 针脚 in 引脚:
title_element = await pin.query_selector("a")
标题 = await title_element.get_attribute("aria-label") if 标题元素 else "无标题"
pin_url = await title_element.get_attribute("href") if 标题元素 else "无 URL"
图像元素 = await pin.query_selector("img")
image_url = await image_element.get_attribute("src") if 图像元素 else "无图像"
results.append({"title": title, "url": pin_url、 "图像": image_url})
await browser.close()
return 成果
async def main():
查询 = "家居装饰"
data = await scrape_pinterest(query)
with open(f"{query}_pins.json", "w") as file:
json.dump(data, file, indent=4)
if __name__ == "__main__":
asyncio.run(main())
如何使用
- 打开 Pinterest 并搜索关键字。
- 等待页面加载。
- 查找页面上的所有插针。
- 提取每个图钉的标题、URL 和图片。
- 将数据保存在 JSON 文件中。
这种方法很有用,但如果 Pinterest 检测到自动搜索,就会阻止这种方法。
使用 Bright Data 的 Scraper API 搜索 Pinterest
Bright Data 提供了一个网络刮板 API,让您可以轻松收集 Pinterest 数据,而不必担心浏览器自动化或被屏蔽。
步骤 1:安装请求
pip install requests
步骤 2:使用 Bright Data 的应用程序接口
import requests
import json
import 时间
API_KEY = "YOUR_API_KEY"
关键词 = "家居装饰"
def start_scrape(api_key, 关键字):
url = "https://api.brightdata.com/datasets/v3/trigger"
headers = {"Authorization": f "承载器 {api_key}", "内容类型": "application/json"}
数据 = [{"关键字": 关键字}]
response = requests.post(url, headers=headers, json=data)
return response.json().get("快照 ID")
def 获取结果(api_key, snapshot_id):
url = f "https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {"Authorization": f "承载器 {api_key}"}
while True:
response = requests.get(url, headers=headers)
if response.status_code == 200:
with open("pinterest_data.json", "w") as 文件:
json.dump(response.json(), file, indent=4)
print("数据已保存!")
break
如果 response.status_code == 202:
print("等待数据......")
time.sleep(10)
else:
print("Error:", response.text)
break
if __name__ == "__main__":
snapshot_id = start_scrape(API_KEY, KEYWORD)
get_results(API_KEY, snapshot_id)
如何使用
- 向 Bright Data 发送请求以开始爬取。
- 等待数据处理。
- 下载并保存结果。
Bright Data 的 API 可靠、快速,并能避免 Pinterest 的拦截。查看 所有其他顶级搜索 API.
您应该使用哪种方法?
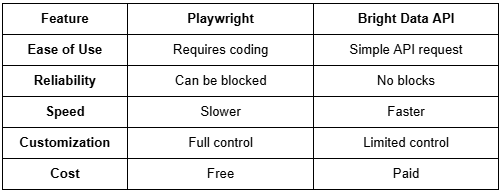
结论
如果你有合适的工具,搜索 Pinterest 是完全可行的。如果你喜欢完全控制并不介意处理一些障碍,Playwright 是个不错的选择。它能让你像真实用户一样与 Pinterest 互动,但你可能会遇到障碍。
如果您需要更简单、更可靠的服务,Bright Data 的 API 将是您的不二之选。它可以为您处理一切事务,无需处理验证码或被阻止的请求。
这两种方法都能帮助你收集 Pinterest 数据,用于研究、营销或内容创作。关键在于哪种方法最适合你。选择适合你的方法,然后开始搜索!







{kind=link}