

如何使用 Python 爬取 Google Finance
设置和要求
在深入学习代码之前,我们先来设置必要的工具和库。您需要在机器上安装 Python 以及 BeautifulSoup 和 Requests 库。
安装 Python 和所需库函数
首先,确保已安装 Python。如果没有,可以从 Python 官方网站.
接下来,运行以下命令安装 BeautifulSoup 和 Requests 库:
pip install beautifulsoup4
pip install requests
了解 Google Finance结构
要有效地从 谷歌财经因此,了解其结构至关重要。Google 财经页面由各种元素组成,其中包括股票价格、标题和其他财务细节。通过检查 HTML 结构,您可以确定包含所需数据的类和标记。
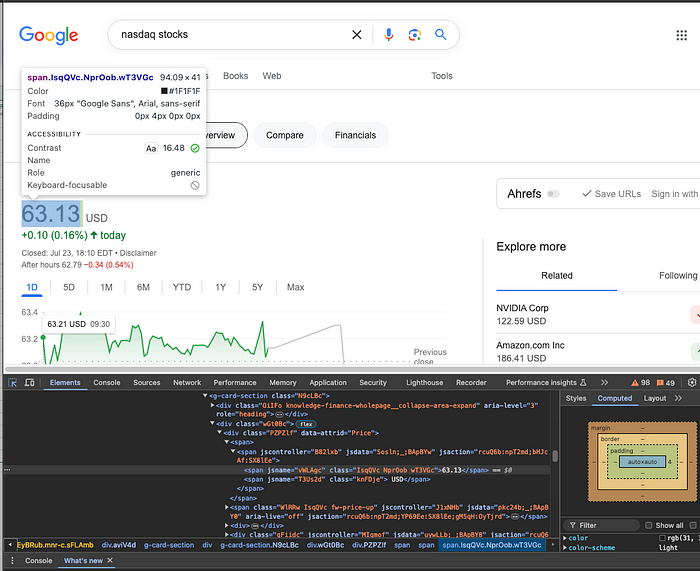
选择目标
基本扫描技术
让我们从一个基本脚本开始,从谷歌财经中抓取股票数据。
脚本示例
下面是一个简单的 Python 脚本,用于提取股票价格、标题和变动情况
import requests
from bs4 import BeautifulSoup
def get_stock_data(ticker): url = f'https://www.google.com/finance/quote/{ticker}?hl=en' response = requests.get(url) soup = BeautifulSoup(response.content, 'html.parser') stock_data = {} stock_data['title'] = soup.find('div', class_='zzDege').text stock_data['price'] = soup.find('div', class_='AHmHk').text stock_data['price_change'] = soup.find('div', class_='JwB6zf').text 返回股票数据print(get_stock_data('AAPL:NASDAQ'))
该脚本使用 Requests 库获取 Google 财经页面的 HTML 内容,然后使用 BeautifulSoup 对其进行解析并提取相关数据。
高级搜索技术
对于更复杂的刮擦任务,您可能需要处理动态内容并避免 IP 屏蔽。使用 Scrapy 或 Selenium 等高级库可以帮助解决这些难题。
使用 Scrapy 处理动态内容
Scrapy 是一个功能强大的网络抓取框架,可以处理更复杂的抓取任务。下面是一个如何使用 Scrapy 从 Google Finance 搜刮数据的示例:
import scrapy
class FinanceSpider(scrapy.Spider): name = 'finance start_urls = ['https://www.google.com/finance/quote/AAPL:NASDAQ?hl=en'] def parse(self, response): yield { 标题": response.css('div.zzDege::text').get()、 price': response.css('div.AHmHk::text').get()、 price_change': response.css('div.JwB6zf::text').get()、 }
避免 IP 屏蔽
为避免刮擦时被阻止,可考虑使用网络刮擦 API,如 谷歌金融应用程序接口 由 Oxylabs 提供。该 API 可帮助您可靠地抓取数据,而无需担心 IP 屏蔽问题。
常见问题的故障排除
网络搜刮有时会导致一些问题,如遇到验证码或被服务器阻止。下面是一些常见问题的故障排除技巧:
- 处理验证码:使用验证码解决服务或 Selenium 等浏览器自动化工具来浏览验证码。
- 避免 IP 屏蔽:使用代理服务器轮换 IP 地址或使用网络搜索 API。
最佳实践与道德考量
从网站上抓取数据时,必须遵守道德准则,尊重网站的服务条款。始终确保你的搜刮活动不违反网站的使用政策。
结论
对于开发人员来说,网络搜刮是一项非常有价值的技能,可让您从各种来源中提取和利用数据,例如 谷歌财经.按照本指南中概述的步骤,您可以使用 Python 高效地搜索财务数据并增强您的项目。
常见问题
什么是网页抓取?
网络抓取是使用自动脚本从网站上提取数据的过程。
爬取 Google Finance 是否合法?
搜索 Google 财经须遵守其服务条款。请始终确保您的搜索活动符合网站政策。
有哪些最佳网络搜索工具?
常用的网络搜刮工具包括 BeautifulSoup、Scrapy 和 Selenium。
如何避免在爬取时受阻?
使用代理服务器、轮换 IP 地址,并考虑使用类似于 谷歌金融应用程序接口.
我可以从其他金融网站获取数据吗?
是的,用于搜索 Google 财经的技术可以应用于其他财经网站,前提是您必须遵守这些网站的服务条款。
通过实施这些策略和最佳实践,您可以有效地从以下网站搜索数据 谷歌财经 并将其集成到您的应用程序中。祝您刮削愉快!







){kind=link}