

How to Bypass CAPTCHAs with Scrapy
In this guide, I’m going to show you how I deal with CAPTCHAs when using Scrapy. I’ll walk you through the methods I use to bypass them, so you can keep your scraper running smoothly without constant interruptions.
What is CAPTCHA?
CAPTCHA stands for “Completely Automated Public Turing test to tell Computers and Humans Apart.” In simple words, it’s a test used to tell whether a visitor is a human or a bot.
CAPTCHA types include:
- Image selection tests (choose all squares with a car).
- Text-based puzzles (type the letters you see).
- ReCAPTCHA from Google (I’m not a robot checkbox).
- Invisible CAPTCHAs (run in the background and block bots silently).
Why Scrapy Scrapers Get Blocked
Scrapy is efficient and fast. But that’s also a problem. Bots often make many requests very quickly. Servers detect these patterns and activate CAPTCHA.
Here are some reasons Scrapy scrapers face CAPTCHA:
- Repeated visits from the same IP address.
- No proper browser headers.
- Requests made too quickly.
- Missing JavaScript execution.
Now let’s explore how to beat CAPTCHA when using Scrapy.
Method 1: Use a Web Scraping API
The easiest way to bypass CAPTCHA is by using a scraping API. These APIs are made to handle everything for you — proxies, CAPTCHAs, and JavaScript rendering.
What is a Web Scraping API?
It’s a service that fetches data for you. You send your target URL, and the API gives you the page data after solving CAPTCHA and avoiding blocks.
How It Works
- You send a request with the target URL.
- The API handles all bot protection.
- You receive the clean HTML content.
Best Tools
Here are some top scraping APIs:
- Bright Data
- ScraperAPI
- Smartproxy
- Oxylabs
- Apify
Example with Bright Data
Let’s see how to use Bright Data with Scrapy.
Step 1: Sign up for Bright Data
Go to their website and create an account. Get your API credentials.
Step 2: Send a Request
import scrapy
import requests
class APISpider(scrapy.Spider):
name = 'api_spider'
def start_requests(self):
url = "https://target-website.com"
proxy_url = f"https://brd.superproxy.io:22225"
response = requests.get(
"https://example-api.brightdata.com",
params={"url": url, "render": "true"},
auth=('username', 'password') # Replace with your API credentials
)
yield scrapy.http.HtmlResponse(
url=url,
body=response.text,
encoding='utf-8'
)
This approach is quick and avoids most CAPTCHAs.
Method 2: Use CAPTCHA-Solving Services
Another way to bypass CAPTCHA is by using solving services. These services use humans or AI to solve CAPTCHAs for you.
Popular Solving Services
- Bright Data’s CAPTCHA Solver
- 2Captcha
- Anti-Captcha
- DeathByCaptcha
- CapMonster
These platforms give you an API key. You send them the CAPTCHA, and they return the answer.
Example with 2Captcha
Let’s solve a reCAPTCHA with 2Captcha using Scrapy.
Step 1: Install Library
pip install 2captcha-python
Step 2: Get API Key
Sign up at 2Captcha and copy your API key from the dashboard.
Step 3: Scrapy Spider with CAPTCHA Solver
import scrapy
from twocaptcha import TwoCaptcha
class CaptchaSpider(scrapy.Spider):
name = 'captcha_spider'
start_urls = ["https://site-with-captcha.com"]
def solve_captcha(self, site_key, url):
solver = TwoCaptcha('YOUR_API_KEY')
try:
result = solver.recaptcha(sitekey=site_key, url=url)
return result.get('code')
except Exception as e:
self.logger.error(f"Error solving CAPTCHA: {e}")
return None
def parse(self, response):
site_key = "SITE_KEY_FROM_HTML"
captcha_code = self.solve_captcha(site_key, response.url)
if captcha_code:
self.logger.info("CAPTCHA Solved!")
# Continue scraping using captcha_code
This approach is useful for forms and login pages that use reCAPTCHA.
Method 3: Rotate Premium Proxies
A smart way to avoid CAPTCHAs is to use different IP addresses. This hides your bot’s identity and reduces the chance of hitting a CAPTCHA.
What Are Rotating Proxies?
Rotating proxies give you a new IP address for every request. They prevent websites from detecting scraping patterns.
Types of Proxies
- Datacenter Proxies (cheap but easier to detect)
- Residential Proxies (more expensive but harder to block)
- Mobile Proxies (very powerful but costly)
Using Proxies in Scrapy
Edit the Scrapy settings file (settings.py) and add proxy settings.
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 1,
'myproject.middlewares.RandomProxy': 100,
}
PROXY_LIST = [
"http://user:pass@ip1:port",
"http://user:pass@ip2:port",
# Add more proxies9
]
Then create a middleware that selects a random proxy.
import random
class RandomProxy:
def process_request(self, request, spider):
proxy = random.choice(spider.settings.get('PROXY_LIST'))
request.meta['proxy'] = proxy
This rotates proxies and reduces your chances of facing CAPTCHA.
Method 4: Use Headless Browsers
Sometimes, Scrapy alone can’t deal with JavaScript-heavy websites. Some CAPTCHAs load with JavaScript and cannot be handled directly.
To fix this, you can use headless browsers like:
- Selenium
- Playwright
- Splash (for Scrapy)
Using Splash with Scrapy
Splash is a JavaScript rendering service built for Scrapy.
Step 1: Install Splash
You can run it with Docker:
docker run -p 8050:8050 scrapinghub/splash
Step 2: Add Middleware
In settings.py:
DOWNLOADER_MIDDLEWARES.update({
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
})
SPIDER_MIDDLEWARES.update({
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
})
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
Step 3: Use SplashRequest
from scrapy_splash import SplashRequest
class JSPageSpider(scrapy.Spider):
name = 'js_page'
start_urls = ['https://example-js-page.com']
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url, self.parse, args={'wait': 2})
Best Practices to Avoid CAPTCHA
Even without fancy tools, there are simple things you can do to avoid CAPTCHA:
1. Use User-Agent Headers
Always use real browser headers to look like a normal user.
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
2. Slow Down Your Requests
Add delays between requests to avoid suspicion.
DOWNLOAD_DELAY = 2
3. Use Cookies
Save and reuse session cookies when scraping. This makes your bot look consistent.
4. Use Referer and Accept Headers
Add headers to mimic real browser behavior.
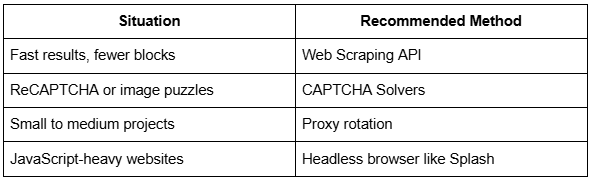
Which Method Should You Choose?
Final Thoughts
CAPTCHAs are everywhere, and they are getting smarter. But you don’t need to give up on your Scrapy project. With the right tools and methods, you can bypass almost any CAPTCHA.
Use APIs for convenience, solvers when necessary, rotate proxies to stay anonymous, and always mimic human behavior with headers and delays.
With these tools in your toolkit, you can keep scraping safely and efficiently.







{kind=link}