

Scrapy vs. Requests: Which One Should You Choose?
In this guide, I’ll explain what makes Scrapy and Requests different and help you decide which one is best for your project. Whether you’re just starting out or planning something big, this article will give you the clarity you need to make the right choice. Let’s dive in!
What is Scrapy?
Scrapy is a complete web scraping framework. It was built to handle everything — sending requests, downloading pages, extracting data, and saving it. It can crawl multiple pages and follow links automatically.
You can think of Scrapy as a smart robot that knows how to navigate many web pages, collect data, and stay organized.
Key Features of Scrapy:
- Can follow links and scrape many pages
- Built-in tools to clean and save data
- Works well with large websites
- Supports concurrent requests (fast)
- Has its system for handling errors and delays
What is Requests?
Requests is a simple Python library that allows you to send HTTP requests. It helps you connect to websites and download the content of a web page. But that’s about it.
It doesn’t know how to extract data from the HTML you get. You will need another library like BeautifulSoup to do that.
Key Features of Requests:
- Easy to use
- Great for downloading one or a few pages
- Works well with APIs
- Lightweight and fast
- Not made for full web crawling
How Do They Work?
Let’s see a simple example:
Using Requests:
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.title.text)
In this code:
- You download the page with requests.get()
- You use BeautifulSoup to parse the HTML and get the title
Using Scrapy:
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example'
start_urls = ['http://example.com']
def parse(self, response):
title = response.css('title::text').get()
print(title)
In Scrapy:
- You define a spider that knows what to scrape and where to go
- Scrapy handles the requests and responses for you
- You write parsing logic inside the parse() method
When to Use Scrapy
Scrapy is designed for serious scraping projects. It is fast, flexible, and efficient. You can build spiders that crawl hundreds or thousands of pages. You should use Scrapy when:
- You want to scrape many pages
- You need to follow links automatically
- You want to save data to a file or database
- You are building a complex scraper
- You want to schedule and repeat scraping jobs
When to Use Requests
If you just want to download one page and extract a few pieces of data, Requests is more than enough. Requests is best when:
- You only want to scrape one or two pages
- You are working with simple APIs
- You are just starting out and learning
- You don’t need to follow links
- You want something quick and easy
Comparing Scrapy and Requests Side-by-Side
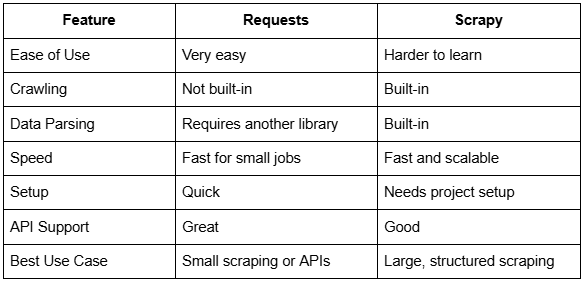
Which One is Faster?
For small tasks, Requests might feel faster because it has less overhead. You just write a few lines of code and get results.
But Scrapy is actually more efficient for bigger jobs. It uses asynchronous requests, which means it can fetch multiple pages at the same time.
So in real-world scraping:
- Requests is faster for tiny tasks
- Scrapy is better for large-scale work
What About Anti-Bot Protection?
Many websites block scrapers. They use firewalls or check for bots.
To avoid being blocked, you can:
- Change your user-agent
- Add delays between requests
- Use proxies
Both Requests and Scrapy support these methods.
However, Scrapy has better support for handling these tricks. You can add middleware, rotate proxies, and use advanced settings to act more like a real user.
You can use a professional web scraping platform like Bright Data for more advanced protection.
Using Professional Proxy & Scraping Tools
Professional web scraping tools like Bright Data and Apify can help you overcome anti-bot challenges when using either Scrapy or Requests. Both companies provide access to large proxy networks — including residential, datacenter, and mobile IPs — as well as additional features like proxy rotation, session control, and geo-targeting.
These services help reduce blocks and maintain scraper reliability, especially when working with websites that have strong bot detection measures or require access from specific regions. Integrating such tools with Python-based scraping workflows can result in a higher success rate and smoother data collection, regardless of your chosen framework.
How Bright Data Helps You Avoid Getting Blocked?
Bright Data is a powerful web scraping solution that offers tools like rotating proxies, residential IPs, and browser-based scraping.
You can use Bright Data with both Scrapy and Requests to:
- Rotate IPs automatically
- Avoid CAPTCHAs
- Bypass JavaScript-heavy websites
- Scale your scraping jobs without being blocked
Example with Requests:
import requests
proxies = {
"http": "http://your_brightdata_proxy",
"https": "http://your_brightdata_proxy",
}
headers = {
"User-Agent": "Mozilla/5.0"
}
response = requests.get('http://example.com', proxies=proxies, headers=headers)
print(response.text)
Bright Data handles many of the headaches of scraping, so your scraper doesn’t get blocked or blacklisted.
It also integrates smoothly with Scrapy through middleware or proxy settings.
Learning Curve
Requests is beginner-friendly. You can learn it in minutes and write working code right away.
Scrapy takes longer to learn. You need to create a project, write spiders, and understand how it works.
If you’re just starting out, begin with Requests. Later, when you’re ready to build more advanced tools, switch to Scrapy.
Can You Use Both Together?
Yes! You can actually use Requests and Scrapy in the same project. For example:
- Use Requests to get data from an API
- Use Scrapy to crawl websites and collect pages
Each tool does its job well, and they can work side-by-side if needed.
Advantages of Scrapy
- Full-featured scraping system
- Built for crawling
- Handles errors better
- Can save data in many formats (JSON, CSV, databases)
- Works with multiple pages at once
Advantages of Requests
- Lightweight and simple
- Great for testing and small projects
- Easy to debug
- Works well with APIs
- Flexible with external parsers
Example Projects Where Scrapy Wins
Here are some tasks where Scrapy is the better choice:
- Scraping all product data from an e-commerce website
- Building a crawler that moves through a blog’s pages
- Creating a job listings scraper that checks multiple sites daily
- Extracting news articles from hundreds of news pages
Scrapy shines when the work is complex and repetitive.
Example Projects Where Requests Wins
These are situations where Requests is more suitable:
- Getting data from a weather API
- Scraping the title and description of one web page
- Writing a quick script to check website status
- Parsing one page of contact details
Requests is perfect for small, focused jobs.
Common Mistakes to Avoid
With Requests:
- Forgetting to check response.status_code
- Not using a parser (like BeautifulSoup)
- Making too many requests too quickly and getting blocked
With Scrapy:
- Not using the correct selectors
- Overcomplicating simple tasks
- Ignoring built-in features like pipelines
What About JavaScript Websites?
Scrapy and Requests both have trouble with JavaScript-heavy pages. These are pages where content is loaded after the page is first opened.
To deal with this, you can:
- Use Selenium or Playwright (for real browsers)
- Use Bright Data, which provides browser-based scraping capabilities and headless browser support
Conclusion
Scrapy and Requests are both excellent tools for web scraping with Python. The one you choose depends on your project goals.
Requests are perfect for small tasks, while Scrapy easily handles big scraping jobs. If you’re dealing with blocks, CAPTCHAs, or JavaScript issues, Bright Data is the best solution to make your scraping projects smooth and reliable.
Start small, grow your skills, and let the right tool support your success!







{kind=link}