

Scrapy 与 Requests:您应该选择哪一个?
在本指南中,我将解释是什么使得 Scrapy 和 Requests 这篇文章将帮助您了解各种不同的设计方案,并帮助您决定哪种方案最适合您的项目。无论您是刚刚起步还是正在筹划大项目,本文都将为您提供做出正确选择所需的清晰思路。让我们深入了解!
什么是 Scrapy?
Scrapy 是一个完整的网络抓取框架。它可以处理发送请求、下载页面、提取数据和保存数据等一切事务。它可以抓取多个页面并自动跟踪链接。
你可以把 Scrapy 想象成一个智能机器人,它知道如何浏览众多网页、收集数据并保持条理清晰。
Scrapy 的主要功能
- 可跟踪链接并抓取多个页面
- 清理和保存数据的内置工具
- 适用于大型网站
- 支持并发请求(快速)
- 有处理错误和延误的系统
什么是Requests?
Requests 是一个简单的 Python 库,可让您发送 HTTP 请求.它可以帮助你连接网站并下载网页内容。但也仅此而已。
它不知道如何从获得的 HTML 中提取数据。您需要另一个库(如 BeautifulSoup)来完成这项工作。
Requests的主要特点:
- 易于使用
- 非常适合下载一页或几页
- 与应用程序接口配合良好
- 轻便快捷
- 不适合全网抓取
它们是如何工作的?
让我们来看一个简单的例子:
使用Requests:
import requests
from bs4 import BeautifulSoup
url = 'http://example.com'
response = requests.get(url)
soup = BeautifulSoup(response.text、 html.parser)
print(soup.title.text)
在此代码中
- 使用 requests.get() 下载页面
- 使用 BeautifulSoup 解析 HTML 并获取标题
使用 Scrapy:
import scrapy
class 示例蜘蛛(scrapy.Spider):
name = 例子
start_urls = ['http://example.com']
定义 parse(自我、响应):
title = response.css('title::text').get()
print(title)
在 Scrapy 中:
- 您定义了一个蜘蛛,它知道该刮什么,该去哪里
- Scrapy 为您处理请求和响应
- 在 parse() 方法中编写解析逻辑
何时使用 Scrapy
Scrapy 专为严肃的刮擦项目而设计。它快速、灵活、高效。您可以构建可抓取成百上千个页面的蜘蛛。在以下情况下应使用 Scrapy
- 您想搜索许多页面
- 您需要自动跟踪链接
- 您想将数据保存到文件或数据库中
- 您正在构建一个复杂的刮板
- 您想安排和重复刮削工作
何时使用Requests
如果您只想下载一个页面并提取一些数据,Requests 就足够了。Requests 最适合用于以下情况
- 您只想搜索一两个页面
- 您正在使用简单的应用程序接口
- 您刚刚开始学习
- 您无需跟踪链接
- 您需要简单快捷的服务
并排比较 Scrapy 和 Requests
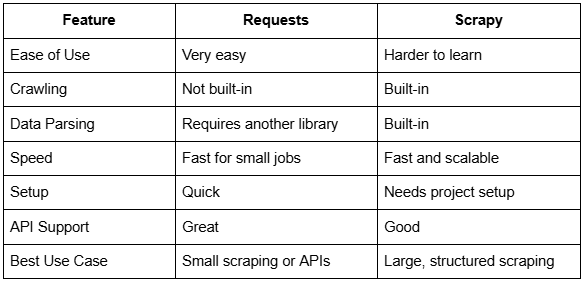
哪个更快?
对于小型任务,Requests 可能会感觉更快,因为它的开销更少。你只需编写几行代码,就能得到结果。
但实际上,Scrapy 对更大的工作更有效率。它使用异步请求,这意味着它可以同时获取多个页面。
因此,在现实世界中刮削:
- 请求处理微小任务的速度更快
- Scrapy 更适合大规模工作
反僵尸保护是什么?
许多网站会阻止刮擦程序。它们使用防火墙或检查机器人。
为避免被屏蔽,您可以
- 更改用户代理
- 增加请求之间的延迟
- 使用代理
Requests 和 Scrapy 都支持这些方法。
不过,Scrapy 对处理这些技巧有更好的支持。你可以添加中间件、 轮换代理并使用高级设置,让自己更像一个真正的用户。
您可以使用 Bright Data 这样的专业网络搜刮平台来提供更高级的保护。
使用专业代理和搜索工具
专业网络搜索工具,如 Bright Data 和 Apify 可以帮助您在使用 Scrapy 或 Requests 时克服反僵尸挑战。两家公司都提供对大型代理网络(包括住宅、数据中心和移动 IP)的访问,以及代理轮换、会话控制和地理定位等附加功能。
这些服务有助于减少阻塞并保持刮擦可靠性,尤其是在处理具有强大僵尸检测措施或需要从特定区域访问的网站时。将此类工具与基于 Python 的刮擦工作流程相结合,无论您选择何种框架,都能提高成功率,使数据收集更加顺畅。
Bright Data 如何帮助您避免受阻?
Bright Data 是一款功能强大的网络搜索解决方案,提供旋转代理等工具、 住宅 IP以及基于浏览器的刮擦。
您可以将 Bright Data 与 Scrapy 和 Requests 结合使用:
- 自动轮换 IP
- 避免验证码
- 绕过 JavaScript 繁重的网站
- 在不受阻的情况下扩展你的刮擦工作
请求示例:
import 请求
代理 = {
"http": "http://your_brightdata_proxy",
"https": "http://your_brightdata_proxy",
}
标题 = {
"User-Agent": "Mozilla/5.0"
}
response = requests.get('http://example.com', 代理服务器=代理服务器, 标头=标头)
print(response.text)
Bright Data 可以处理许多令人头疼的搜索问题,因此您的搜索器不会被阻止或列入黑名单。
它还可以通过中间件或代理设置与 Scrapy 平滑集成。
学习难度
Requests 对初学者非常友好。您可以在几分钟内学会并立即编写工作代码。
学习 Scrapy 需要更长的时间。你需要创建一个项目,编写蜘蛛程序,并了解它的工作原理。
如果你刚刚开始,可以从 Requests 开始。稍后,当你准备好构建更高级的工具时,再切换到 Scrapy。
两者可以同时使用吗?
是的!您可以在同一个项目中使用 Requests 和 Scrapy。例如
- 使用请求从应用程序接口获取数据
- 使用 Scrapy 抓取网站并收集页面
每种工具都能很好地完成自己的工作,必要时还能并肩作战。
Scrapy 的优势
- 全功能刮削系统
- 专为爬行设计
- 更好地处理错误
- 可以多种格式(JSON、CSV、数据库)保存数据
- 可同时处理多个页面
Requests的优势
- 轻便简单
- 非常适合测试和小型项目
- 易于调试
- 与应用程序接口配合良好
- 灵活使用外部解析器
Scrapy 胜出的项目示例
在某些任务中,Scrapy 是更好的选择:
- 从电子商务网站抓取所有产品数据
- 构建一个爬虫,在博客页面中移动
- 创建一个每日检查多个网站的职位列表搜索器
- 从数百个新闻网页中提取新闻文章
当工作复杂且重复时,Scrapy 就会大显身手。
Requests 获胜的项目示例
在这些情况下,请求书更为合适:
- 从天气 API 获取数据
- 抓取一个网页的标题和描述
- 编写检查网站状态的快速脚本
- 解析一页联系方式
这些要求非常适合小型、集中的工作。
应避免的常见错误
使用 Requests:
- 忘记检查 response.status_code
- 不使用解析器(如 BeautifulSoup)
- 请求太多太快而被阻止
使用 Scrapy:
- 未使用正确的选择器
- 将简单的任务过于复杂化
- 忽略管道等内置功能
JavaScript 网站怎么办?
Scrapy 和 Requests 在处理 JavaScript 较多的页面时都会遇到困难。这些页面的内容是在首次打开后加载的。
要解决这个问题,您可以
- 使用 Selenium 或 Playwright (真正的浏览器)
- 使用 Bright Data其中规定 基于浏览器的刮擦功能 和无头浏览器支持
结论
Scrapy 和 Requests 都是使用 Python 进行网络搜刮的优秀工具。选择哪一个取决于您的项目目标。
Requests 非常适合小型任务,而 Scrapy 则能轻松处理大型搜索任务。如果您需要处理区块、验证码或 JavaScript 问题,Bright Data 是让您的刮擦项目顺利可靠的最佳解决方案。
从小事做起,提高技能,让合适的工具助您成功!







{kind=link}