

5 Best Rust HTML Parsers for Web Scraping
If you’re using Rust (like I am), you’ll want a parser that’s fast, safe, and easy to work with. Luckily, there are a few great libraries out there built just for that. In this guide, I’ll walk you through the 5 best Rust HTML parsers I’ve found for web scraping. I’ll share what each one does well, where it falls short, and when to use it.
Why You Need an HTML Parser in Rust
When you fetch a webpage using a Rust HTTP client like reqwest, you receive the raw HTML content. However, HTML is not easy to read or navigate using basic string methods. HTML parsers let you:
- Search for elements using tags or CSS classes
- Navigate parent-child relationships between elements
- Extract text or attribute values
- Handle broken or malformed HTML
This is especially helpful when scraping real-world websites that don’t always follow perfect HTML rules.
Setup for Testing
Before we dive into the individual libraries, here’s the sample async Rust function we use to get the HTML from a test website:
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let resp = reqwest::get("https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/")
.await?
.text()
.await?;
println!("{}", resp);
Ok(())
}
Top 5 Best Rust HTML Parsers for Web Scraping
Let’s take a closer look at each HTML parser on the list. I’ll show you how they work with real-world HTML and how well they perform.
Scraper — Easy and Reliable
Scraper is a high-level HTML parsing library in Rust. It’s built on top of html5ever and selectors, which means it’s fast and designed to handle messy, real-world HTML.
Key Features:
- High-level interface
- CSS selector support
- Based on real browser technology
- DOM-like HTML tree
Pros:
- Very easy to use
- Can handle broken or invalid HTML
- Active development and community support
- Good documentation
Cons:
- Consumes more memory with large pages
- Limited support for modifying the HTML
Example:
use scraper::{Html, Selector};
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let resp = reqwest::get("https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/")
.await?
.text()
.await?;
let fragment = Html::parse_document(&resp);
let selector = Selector::parse(".price").unwrap();
if let Some(element) = fragment.select(&selector).next() {
let price = element.text().collect::<String>();
println!("Price: {}", price);
}
Ok(())
}
Use Case: Best for most web scraping projects, especially when ease-of-use and real-world compatibility are key.
html5ever — Fast and Low-Level

Html5ever is a fast and powerful HTML parser written in Rust. It was created as part of the Servo browser project. It does not build a full DOM tree. Instead, it uses a tokenizer model, emitting each HTML element as a token.
Key Features:
- Complies with the HTML5 standard
- Very fast parsing
- Used in browser engines like Servo
Pros:
- Extremely fast and efficient
- Handles malformed HTML well
- Full control over HTML structure
- Low-level customization possible
Cons:
- Verbose and harder to use
- No DOM tree representation
- Requires more code to extract specific data
Example:
extern crate html5ever;
use html5ever::tendril::TendrilSink;
use html5ever::tokenizer::{Tokenizer, TokenSink, Token, TokenSinkResult, StartTag, EndTag, CharacterTokens, TokenizerOpts};
use html5ever::tokenizer::BufferQueue;
struct PriceFinder {
inside_price: bool,
result: String,
}
impl TokenSink for PriceFinder {
type Handle = ();
fn process_token(&mut self, token: Token, _line: u64) -> TokenSinkResult<()> {
match token {
Token::TagToken(tag) => {
if tag.kind == StartTag && tag.name.as_ref() == "p" {
for attr in tag.attrs {
if attr.name.local.as_ref() == "class" && attr.value.as_ref() == "price" {
self.inside_price = true;
}
}
} else if tag.kind == EndTag && tag.name.as_ref() == "p" {
self.inside_price = false;
}
}
Token::CharacterTokens(t) => {
if self.inside_price {
self.result.push_str(&t);
}
}
_ => {}
}
TokenSinkResult::Continue
}
}
Use Case: Best for performance-critical scraping or when you want complete control.
Select.rs — jQuery-Style Syntax
Select.rs is another powerful HTML parser for Rust. Its familiar jQuery-style syntax makes it easy to write and understand selectors.
Key Features:
- Supports CSS and XPath-like queries
- Allows DOM modification
- Returns clean output formats like JSON and YAML
Pros:
- jQuery-style syntax
- Easy for beginners
- Can export data in multiple formats
- Built-in functions for finding and editing nodes
Cons:
- Uses more memory than other tools
- Slower than some alternatives for large documents
Example:
use select::document::Document;
use select::predicate::{Class, Name};
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let resp = reqwest::get("https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/")
.await?
.text()
.await?;
let document = Document::from(resp.as_str());
if let Some(price_node) = document.find(Name("p").and(Class("price"))).next() {
println!("Price: {}", price_node.text());
}
Ok(())
}
Use Case: Great for users who prefer jQuery-style syntax and want to output structured data.
Kuchiki — DOM-Like Tree
Kuchiki (Japanese for “rotten tree”) is a fun and intuitive HTML parser that creates a DOM tree, like a real browser. It’s built on html5ever, but provides a tree-based interface with CSS-style selectors.
Key Features:
- DOM tree support
- CSS selectors
- Allows traversal and modification
Pros:
- Very easy to understand
- Full tree structure
- Good selector support
- Great for traversing complex HTML
Cons:
- No longer actively maintained (archived in 2023)
- Larger binary size due to tree handling
Example:
use kuchiki::parse_html;
use kuchiki::traits::*;
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let resp = reqwest::get("https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/")
.await?
.text()
.await?;
let document = parse_html().one(resp);
if let Ok(price_node) = document.select_first("p.price") {
println!("Price: {}", price_node.text_contents());
}
Ok(())
}
Use Case: This is best for tree traversal and simple HTML tasks. It should be avoided for large projects due to the lack of support.
Pulldown-Cmark — Markdown First
Pulldown-cmark is not an HTML parser in the traditional sense. It’s designed to parse Markdown, but it can be adapted for some HTML parsing tasks. It works well when combined with tools like html2md that convert HTML to Markdown.
Key Features:
- Pull parser for Markdown
- Extremely low memory usage
- Can convert HTML → Markdown → parse text
Pros:
- Super lightweight
- Efficient for large text files
- Useful when you only need plain text
- Simple to use
Cons:
- Not a true HTML parser
- Lacks CSS selector or DOM support
- Needs other crates for HTML handling
Example:
use pulldown_cmark::{Parser, Event};
use html2md;
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let resp = reqwest::get("https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/")
.await?
.text()
.await?;
let markdown = html2md::parse_html(&resp);
let parser = Parser::new(&markdown);
for event in parser {
if let Event::Text(text) = event {
if text.contains("$") {
println!("Price: {}", text);
}
}
}
Ok(())
}
Use Case: Great for converting HTML content to Markdown for analysis or display.
Performance Benchmark
We tested each parser using the same webpage and extraction task (extracting product price). Here’s how they performed on average (lower is better):
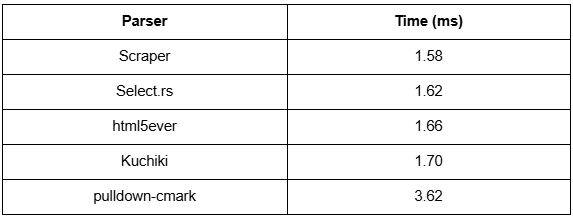
These tests were run using criterion.rs on a Ryzen 9 machine. Real-world results may vary.
When to Use Each HTML Parser
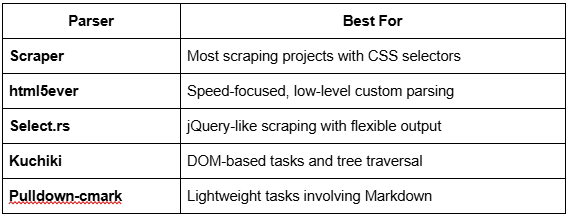
Conclusion
Rust has several capable HTML parsers for web scraping. Whether you want high performance, easy syntax, or advanced control, there’s a crate for you. If you’re just getting started, Scraper is a great balance of power and simplicity. If you care about raw performance and have time to write more code, go for html5ever. For structured output and jQuery-style selection, try Select.rs.
And if you’re converting content to Markdown, Pulldown-cmark may surprise you with its speed. Whichever parser you choose, pair it with a reliable proxies or scraping APIs like Bright Data or ScrapingBee. This ensures your scrapers avoid IP blocks and can scale effectively!







{kind=link}