

Using curl_cffi for Web Scraping in Python
In this article, I’ll introduce you to curl_cffi and show how it can help you scrape websites without encountering roadblocks. Let’s dive in!
What is curl_cffi?
curl_cffi is a Python library that acts as a client for performing HTTP requests. It is built on top of cURL Impersonate, a fork of the popular cURL library. What makes curl_cffi unique is its ability to impersonate the TLS fingerprints of real web browsers. This allows it to bypass advanced bot detection techniques, such as TLS fingerprinting, which is a method used by websites to distinguish between real browsers and automated bots.
How Does curl_cffi Work?
curl_cffi works by impersonating real browsers during the TLS handshake process. Here’s a quick rundown of how the tool works:
- TLS Handshake: A TLS handshake occurs between the client and the server when making an HTTPS request. This handshake involves the negotiation of encryption settings, and the client sends a fingerprint to the server, which helps the server identify the client.
- TLS Fingerprint Mimicking: Using cURL Impersonate, curl_cffi alters the fingerprint to match that of a popular browser like Chrome or Safari. This helps hide the fact that the request is automated.
- HTTP/2 Handshake: curl_cffi also mimics browsers’ specific HTTP/2 handshake settings, providing further stealth.
- Customizable Configurations: The library allows developers to customize TLS settings, such as cipher suites, supported curves, and headers, making the requests appear as if they were made by a real user.
🛡️ Add Residential Proxies for Stealth & Scale
While curl_cffi helps you mimic real browsers, pairing it with Bright Data’s Residential Proxies gives you even more scraping power. These proxies rotate IPs from real devices, helping you avoid blocks and CAPTCHAs — especially when scraping sites like Walmart or running large-scale jobs. It’s the perfect combo for staying undetected and scraping at scale.
Step-by-Step Guide to Using curl_cffi for Web Scraping
Let’s walk through a practical example of how to use curl_cffi for web scraping.
Step 1: Set Up Your Project
Start by setting up a Python environment. This ensures you can manage dependencies and isolate your project from other Python projects. Here are the steps to set up the environment:
Install Python 3.x from the official Python website.
Create a new directory for your project:
mkdir curl-cffi-scraper
cd curl-cffi-scraper
Create a virtual environment in the project directory:
python -m venv env
Activate the virtual environment:
On Windows:
envScriptsactivate
On macOS/Linux:
source env/bin/activate
Step 2: Install curl_cffi
Once your virtual environment is activated, you can install the curl_cffi library:
pip install curl-cffi
This will install curl_cffi along with the necessary cURL impersonation binaries.
Step 3: Import and Configure curl_cffi
Now that the library is installed, you can start writing your scraping script. First, create a Python file (e.g., scraper.py) and import the necessary modules:
from curl_cffi import requests
Now, let’s make a GET request to a target webpage. For this example, we will scrape Walmart’s product search page for the keyword “keyboard”. You can use the impersonate parameter to specify that the request should mimic a specific browser:
response = requests.get("https://www.walmart.com/search?q=keyboard", impersonate="chrome")
This tells curl_cffi to make the request appear as though it’s coming from the latest version of Google Chrome.
Step 4: Extract Data from the Page
Once the page is successfully retrieved, you can parse the HTML content. For this, you can use the BeautifulSoup library. First, install it using:
pip install beautifulsoup4
Now, in your script, parse the page content using BeautifulSoup:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
Let's extract the title of the page:
title_element = soup.find("title")
title = title_element.text
print(title)
This will print the title of the page, such as “Electronics — Walmart.com”, if the scraping request was successful.
Step 5: Run the Scraper
Now, you can run the scraper by executing the Python script:
python scraper.py
If everything works correctly, you will get the page title printed on your terminal. If you did not use the impersonate=”chrome” argument, Walmart would likely show a CAPTCHA or a bot detection page instead.
Advanced Features of curl_cffi
1. Browser Impersonation
curl_cffi supports several browser versions for impersonation. You can specify a browser version when making a request. Here are a few examples:
- Chrome: impersonate=”chrome”
- Edge: impersonate=”edge101″
- Safari: impersonate=”safari17_2_ios”
This allows you to closely match the specific TLS fingerprints of browsers and avoid detection.
2. Session Management
curl_cffi allows you to maintain sessions across multiple requests. This is useful when a website requires authentication or when cookies are used. Here’s how you can create a session and use it for subsequent requests:
session = requests.Session()
session.get("https://httpbin.org/cookies/set/userId/5", impersonate="chrome")
print(session.cookies)
3. Proxy Support
To avoid getting blocked, you can use proxies. curl_cffi allows you to set proxies for both HTTP and HTTPS requests. Here’s an example:
proxies = {"http": "http://your_proxy", "https": "https://your_proxy"}
response = requests.get("https://www.example.com", impersonate="chrome", proxies=proxies)
For most use cases, I suggest using residential proxies. You can take a look at my list of the best residential proxies to choose the perfect provider for your needs.
4. Asynchronous Requests
For scraping multiple pages concurrently, curl_cffi supports asynchronous requests through AsyncSession:
from curl_cffi.requests import AsyncSession
import asyncio
async def fetch_data():
async with AsyncSession() as session:
response = await session.get("https://www.example.com", impersonate="chrome")
print(response.text)
asyncio.run(fetch_data())
Comparing curl_cffi with Other HTTP Clients
Let’s compare curl_cffi with some popular Python HTTP clients for web scraping, such as requests, AIOHTTP, and HTTPX.
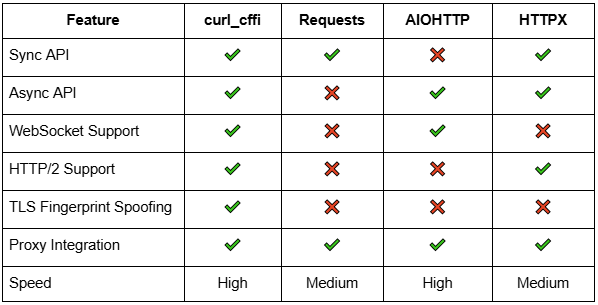 Comparison table between HTTP clients
Comparison table between HTTP clients
Advantages of curl_cffi
- TLS Fingerprint Spoofing: Unlike requests and AIOHTTP, curl_cffi can easily bypass bot detection based on TLS fingerprints.
- Faster Requests: curl_cffi is faster than requests and HTTPX, making it ideal for large scraping tasks.
Conclusion
So, you learned how to use curl_cffi for web scraping in Python. This library allows you to mimic real browser traffic, bypassing advanced anti-bot measures like TLS fingerprinting. You also saw how to integrate BeautifulSoup for HTML parsing, handle asynchronous requests, and manage sessions and proxies. Whether you’re a beginner or an advanced web scraper, curl_cffi offers a powerful and efficient solution for extracting data from websites.
If you need more advanced features or a fully managed scraping service, consider exploring other options like Scraping Browser or Web Scraper APIs. However, for most use cases, curl_cffi provides a simple, fast, and effective way to easily scrape websites.







{kind=link}